From Bunge Bits to Bunge Hub: building Kenya's parliamentary data layer
- 10 minsThis is a story about a problem I kept coming back to, two failed starts, one pivot that changed everything, and a project that is finally built to last.
Where it started: Bunge Bits
Bunge Bits started from a simple observation. The Kenyan Parliament livestreams its sittings on YouTube. Those recordings are publicly available. And yet there was no good way to search what was said, track a specific member’s contributions, or follow a bill through its debates without sitting through hours of video.
The idea was straightforward: transcribe the recordings using AI, summarize the content, and surface it in a searchable interface. I built a pipeline that pulled YouTube livestreams, ran them through a speech-to-text model, then used an LLM to generate summaries of what was discussed.
It worked, technically. The transcripts were readable, the summaries were useful, and a few people in civic and policy circles found it genuinely helpful.
Then the bills arrived.
Cloud LLMs are expensive at scale. Transcribing hours of parliamentary audio and summarizing it sitting by sitting adds up fast. The project had no funding model and no path to one. After a while, the cost of keeping it running outweighed what I could justify spending on a solo side project, and I shut it down.
The lesson I took from Bunge Bits was not that the idea was wrong. It was that I had built on the wrong foundation. AI-generated transcripts as the canonical source of truth is fragile and expensive. Parliament already publishes the official record. I just had not used it.
The pivot: Hansard as the source of truth
Kenya’s official Hansard, the verbatim record of everything said in Parliament, is published through mzalendo.com. It is structured HTML: sections, headings, contributions, speaker names. It is not perfect, but it is the authoritative record, and it is free to read.
The pivot was to stop transcribing audio and start parsing the Hansard directly. This meant building a scraper.
I wrote the first version of what would become odnelazm in Rust. The goal was simple: fetch a sitting’s HTML, parse it into structured types, and make that data accessible programmatically.
The parsing problem turned out to be more interesting than expected. mzalendo actually serves data from two distinct sources with different HTML structures: an archive at info.mzalendo.com covering sittings going back to 2006, and a current tracker at mzalendo.com/democracy-tools/hansard covering 2013 to present. Both needed separate parsers. And within the current source, the HTML structure changed around early 2026, requiring the parser to handle two formats without breaking.
That kind of structural inconsistency is normal when you are reading someone else’s website as data infrastructure. You learn to build defensively.
odnelazm: the scraper and CLI
Once the parser was solid, I wrapped it in a CLI. odnelazm-cli lets you browse and fetch parliamentary data directly from the terminal.
cargo install --git https://github.com/mwananchi-tech/odnelazm odnelazm-cli
# List recent sittings
odnelazm sittings
# Fetch a full sitting transcript (source detected automatically from the URL)
odnelazm sitting thursday-12th-february-2026-afternoon-sitting-2438
# List all members of the 13th Parliament National Assembly
odnelazm members na 13th-parliament --all -o json
# Fetch a member's full profile
odnelazm profile https://mzalendo.com/mps-performance/national-assembly/13th-parliament/boss-gladys-jepkosgei/
It supports both archive and current data sources with automatic routing, outputs JSON, CSV, or Parquet, and handles pagination. It is the kind of tool I wished existed when I was building Bunge Bits.
odnelazm-mcp: asking questions about Parliament in plain English
The next step was making the data accessible to LLM clients. I built odnelazm-mcp, an MCP (Model Context Protocol) server that exposes the scraper as tools, so any compatible client (Claude or ChatGPT) can query parliamentary data directly in conversation.
cargo install --git https://github.com/mwananchi-tech/odnelazm odnelazm-mcp-local
With it connected to Claude Desktop, you can ask things like:
- “Who spoke on the Finance Bill in June 2023?”
- “List all Senate sittings from the first quarter of 2025”
- “What did Gladys Boss Shollei say about housing?”
The server handles the fetching and parsing transparently. The LLM reasons over the structured data.
The limitation is context. Hansard transcripts are large. A single sitting can run to tens of thousands of tokens. Fetching multiple sittings, or a member’s full activity history, can easily exceed the context window of most models. The practical guidance is to keep queries narrow: one sitting at a time, one date range at a time. For broad cross-sitting queries, a local model with a large context window (1M+ tokens) handles it better.
Bunge Hub: the full picture
odnelazm as a scraper and CLI is useful for developers and researchers who are comfortable in a terminal. But most people who care about parliamentary accountability are not that audience.
Bunge Hub is the web layer on top of the same data. It runs a PostgreSQL database populated by odnelazm-pipeline, which handles ingesting sittings, extracting bills and topics, importing member profiles, and linking speaker records to canonical member identities.
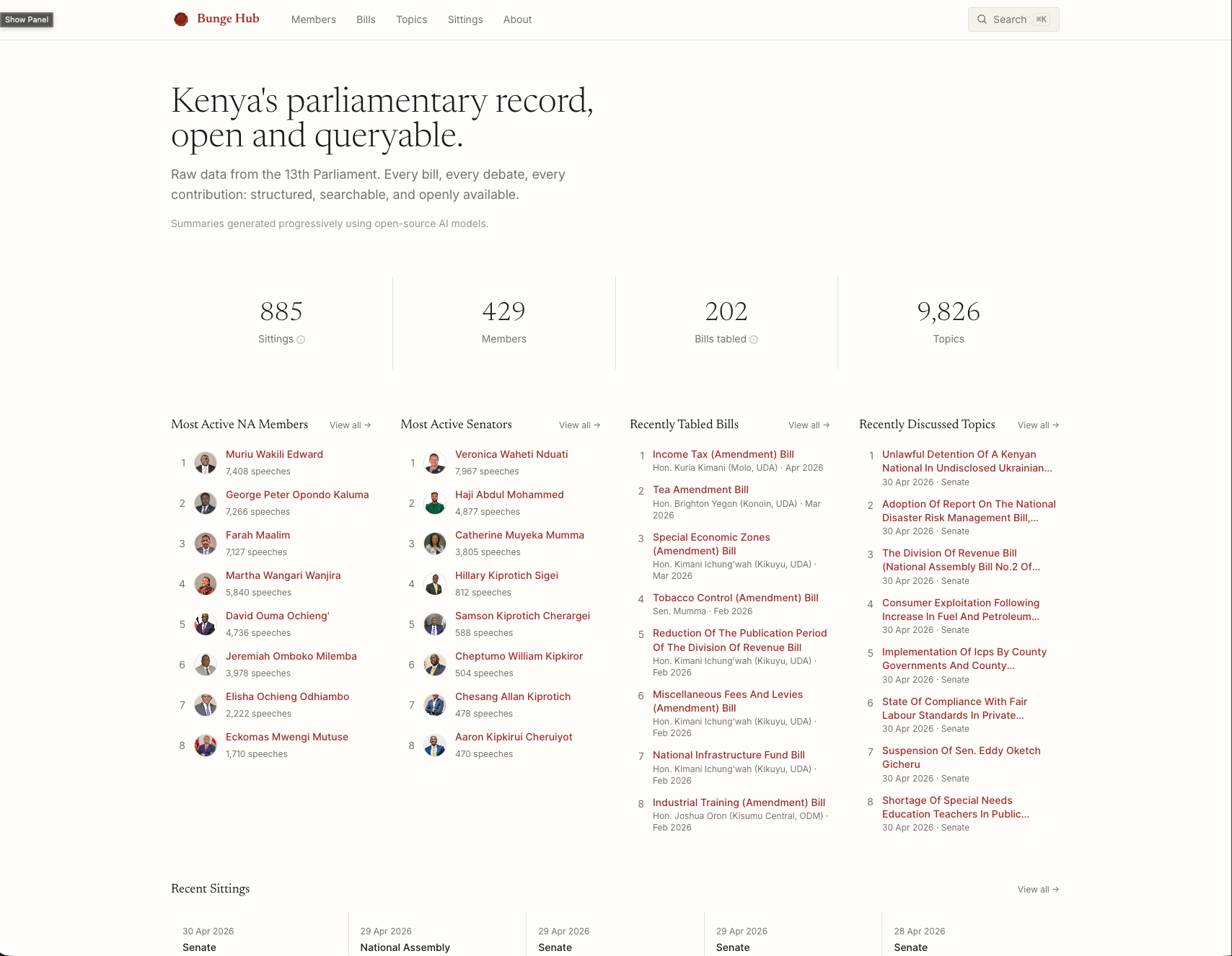
The data model that emerged from this is something I am genuinely proud of. 885 sittings, 391 bills, 9,826 topics, 3,001 speaker records linked where possible to 429 members. You can trace a bill through every sitting it appeared in, see who spoke at each stage, and read their contributions side by side.
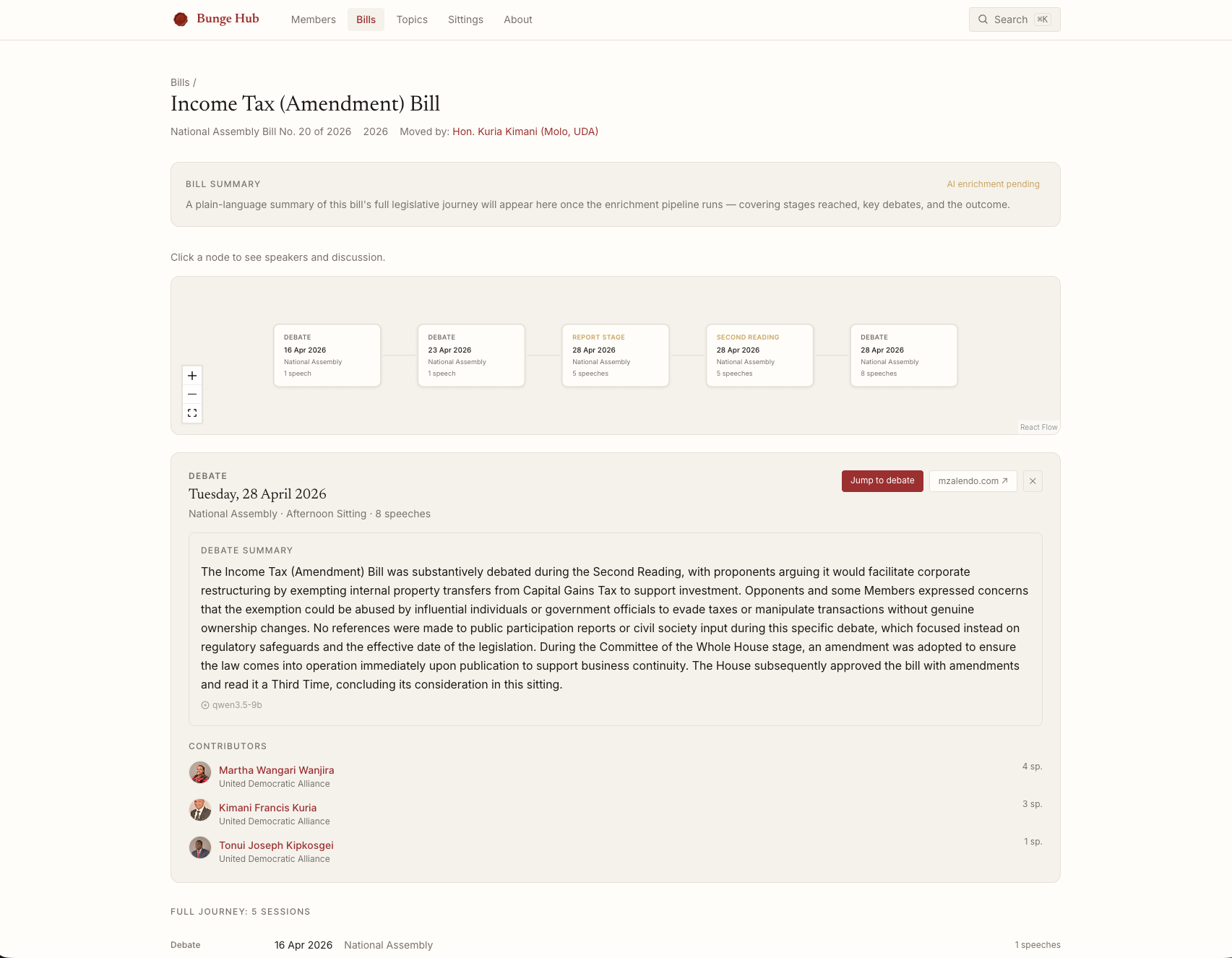
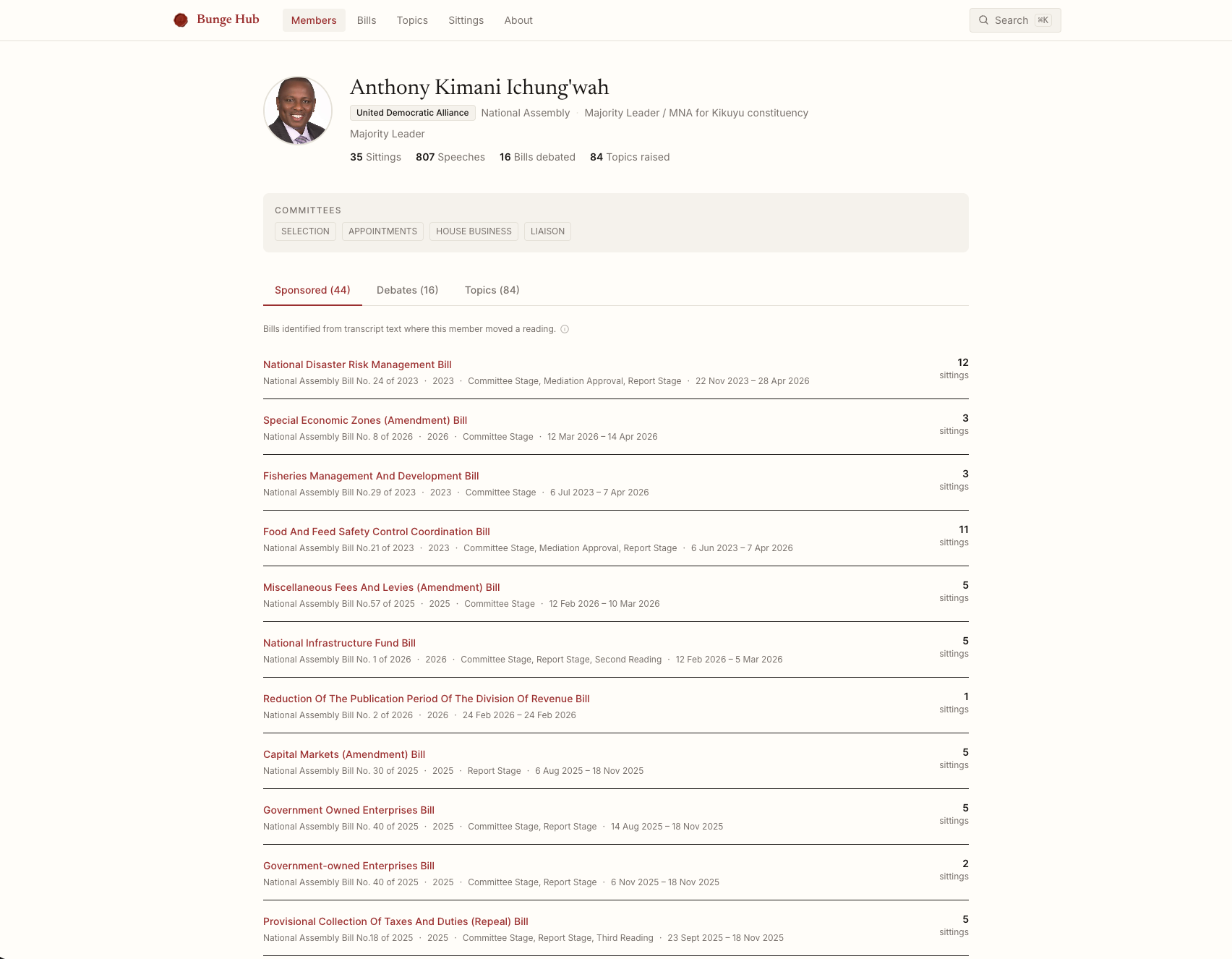
The linking problem, matching a speaker name extracted from a transcript to a canonical member record, turned out to be one of the harder engineering problems in the project. The same person appears as “Hon. Kaluma”, “George Kaluma”, “Peter Kaluma” across different sittings. The solution combines exact URL matching (when mzalendo includes a profile link), fuzzy trigram similarity via pg_trgm, and a handful of special cases, like the Speaker of the National Assembly, whose contributions are labelled “Hon. Speaker” and do not fuzzy-match anything useful.
On top of this, I added an AI enrichment layer using locally running open-source models via LM Studio. Each bill appearance gets a summary of what was argued and what the outcome was. Each bill’s full journey across Parliament gets a narrative summary. The model used to generate each summary is recorded and displayed in the UI.
Doing it sustainably this time
The core lesson from Bunge Bits was about cost. I am not repeating that mistake.
The enrichment pipeline runs locally. No cloud LLM APIs, no per-token billing, no dependency on a service that can change its pricing or shut down. The tradeoff is throughput: a 9B model on consumer hardware is slow. But the data does not expire. A summary generated this week is just as useful next month.
The architecture is designed so that if better hardware or funding becomes available, swapping to a faster model is a one-line change. Every summary is attributed to the model that generated it, so a future re-enrichment pass can target specific rows selectively.
There is also no funding dependency for the core product. The database and web app cost pennies to host at this scale. The ingest pipeline runs on a cron job. If I step away for six months, the data already in the database stays useful.
One other deliberate decision: I created Mwananchi Tech as an open-source organisation to be the umbrella for these projects, rather than keeping them under my personal GitHub. The practical reason is that associating the work with an organisation rather than an individual makes it easier to attract collaborators and potential partners. If someone wants to contribute or build on top of what is here, they are joining a project, not someone’s personal experiment.
What’s next
Bunge Hub is in its later stages of development. The code is open source at mwananchi-tech/bunge-hub, and a full launch post will be published once it is publicly available.
The current data covers the 13th Parliament (September 2022 to present). The archive goes back to 2006. odnelazm already has a full parser for the archival source at info.mzalendo.com, so extending coverage to earlier parliaments is a matter of running the pipeline, not building new infrastructure.
The other thing I keep thinking about is YouTube. The recordings that Bunge Bits used to transcribe are still there. Now that the Hansard is the canonical source, the opportunity is different: not transcription, but timestamping. If you could link a specific contribution in the structured transcript to the exact moment in the YouTube recording, you could read a debate and click directly to the video. That closes the loop between the written record and the live moment in a way nothing else currently does.
That is a harder problem. But the foundation is now solid enough to build it on.
Why am I doing this?
Honestly, curiosity got me here. There is a genuine gap nobody in the Kenyan tech space has seriously tried to close, and that bothered me enough to do something about it.
I did worry, at some point, about tying my identity too closely to civic tech. It is a niche space and not always the most visible one. But I have stopped caring about that.
There was also a more uncomfortable fear. People who work in civic tech in Kenya get reminded, sometimes only half-jokingly, that Subarus might come for them. That fear is not entirely abstract. What happened to Rose Njeri was a real reminder of the risks that come with this kind of work in this environment. I thought about it. I will not pretend I did not. But I am confident that what I am building is not illegal. All the data I use is publicly available. The Hansard is the official parliamentary record. I am not hacking anything, exposing anything that is not already public, or doing anything I could not defend clearly and loudly if I had to.
A few days ago I attended a Tech and Democracy meetup organized by Sparkable and met some genuinely interesting people working on accountability and governance from different angles. That conversation spurred me on more than anything else has in a while. If this is the cause my name ends up attached to, I am fine with it. It is technically challenging, it is for the greater good, and it is using the latest tooling and AI to bring some meaning to an era where that can be hard to find.
Also, full transparency: I have had a lot of free time. Not working a full-time job at the moment, which is partly how a project this scope got built by one person in under a year. If you are hiring and any of this resonates, I am open to it.